
Many users of Windows computers are familiar with the term ‘blue screen of death’, or BSOD. That’s what you get on your screen when the computer suddenly crashes (stops) due to an unexpected event on the PC. So the computer slams to a halt, throws its hands up in the air and shows you a BSOD.
It’s part of computing life from the very early days when hardware and software were more likely than not to give up the ghost for one reason or another. Today, BSODs are still part of computing life but are relatively rare on workhorse PCs used in businesses and homes around the world. When they do happen on one particular PC, it’s typically little more than an inconvenience, and you can work on a solution yourself. It’s even easier when you have an assistant like ChatGPT at your side.
Now imagine what the situation might be if you had an event that affected literally thousands and thousands of computers running Windows, all around the world, each of which required a human being to be sat at each computer to perform a fix.
A Screwup At Scale
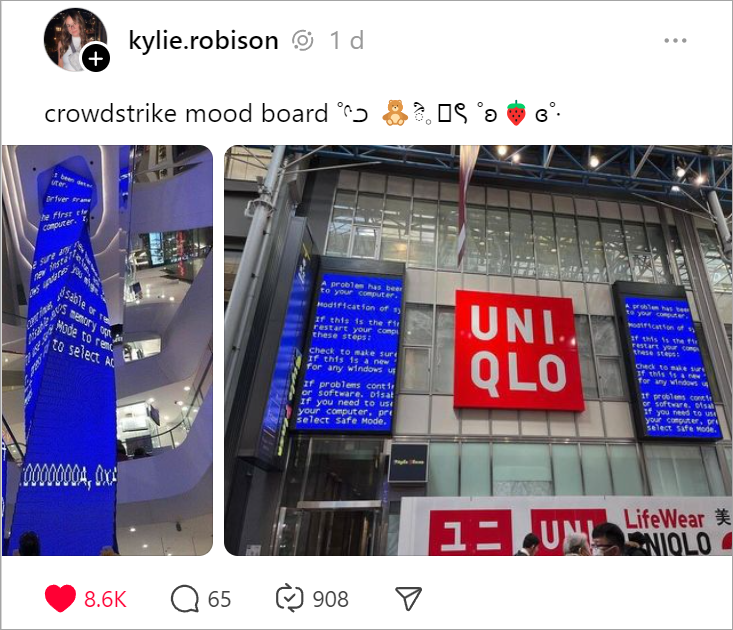
That is what happened last Thursday when a flawed software update from CrowdStrike, an American cybersecurity firm, inadvertently introduced a critical vulnerability to Windows, leading to widespread system failures and significant operational disruptions across businesses of all types all over the world.
We’re not just talking about desktop PCs and laptops. This event also adversely affected the operation of any device running Windows. The impact was immediate and exceptionally disruptive for businesses in many industries, their employees and customers, including airports, banks, broadcasting, hotels, hospitals, manufacturing, retail, schools, stock markets, and transportation.
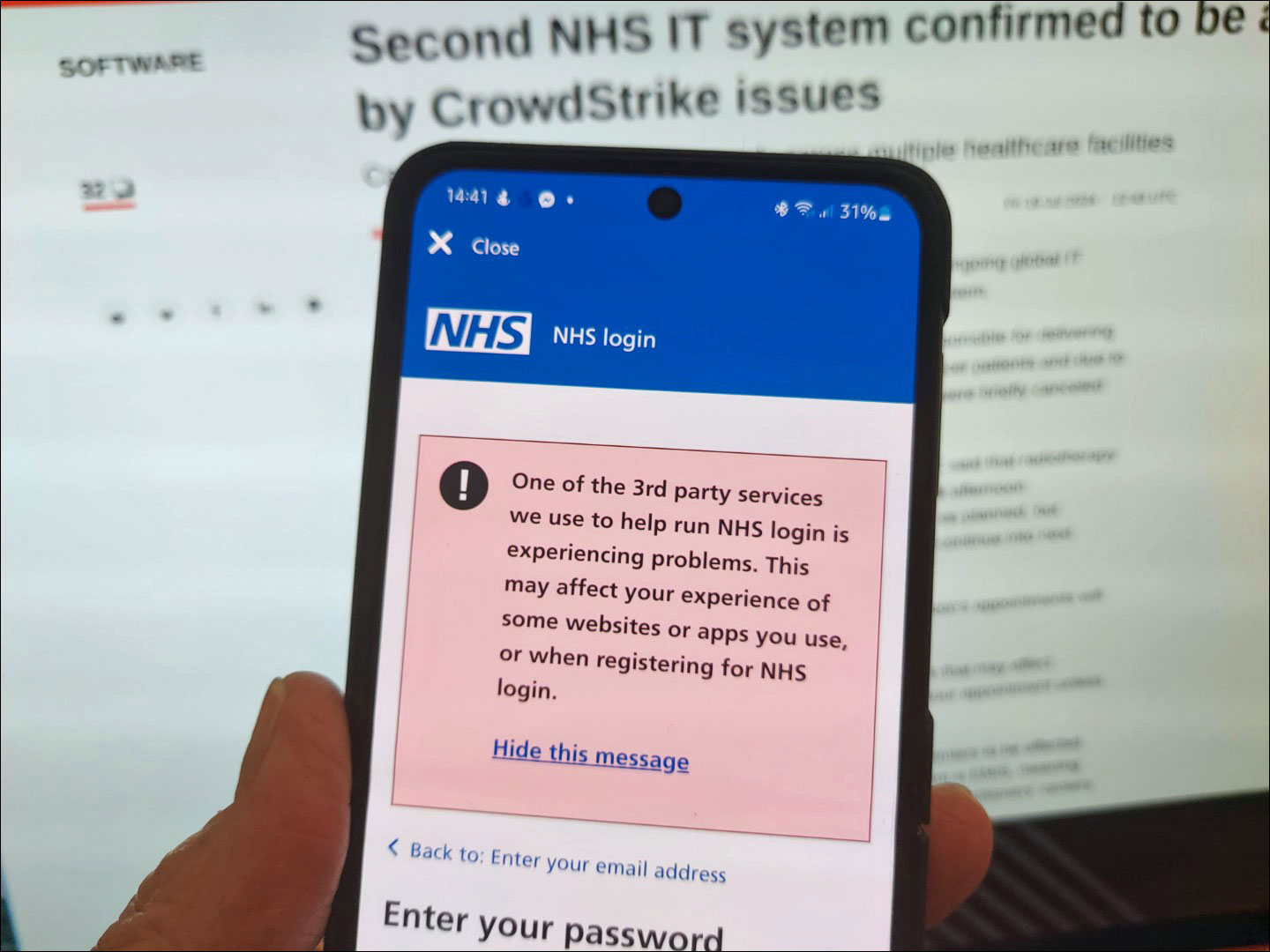
Governmental services including emergency services have been affected, even the NHS health service in the UK, where the effects ranged from problems for patients logging in to their medical records online and via the NHS app (such as the photo at the top illustrates), making appointments with their GP, and even life-challenging disruptions such as cancer patients being unable to attend scheduled radiotherapy sessions at the hospital as the systems were down because of CrowdStrike’s flawed software update.
The global reach of Windows means that no sector has been spared. Microsoft says its current estimate is that CrowdStrike’s faulty update affected 8.5 million Windows devices. Microsoft – the maker of Windows but not the perpetrator of this outage – says this is less than one per cent of all Windows machines. While that offers some perspective on the numbers, it’s small comfort when you consider that the scale of numbers shows that fixing this problem can’t quickly be done at scale (MIT has some handy tips on how to do your own fix).
None of this was the outcome of a cyberattack or an act of terrorism. While it was faulty code that created the meltdown, it appears that this was down to human error at CrowdStrike, a terrifying reminder of the fragility of the centralised systems that knit together our connected world and the people who maintain those systems.
Navigating The Aftermath
It’s all a stark reminder of the vulnerabilities inherent in this interconnected digital world. It underscores the need for rigorous testing and quality assurance in software updates, robust contingency planning, and improved collaboration between cybersecurity firms and their clients. As Microsoft noted on Saturday:
“It’s also a reminder of how important it is for all of us across the tech ecosystem to prioritise operating with safe deployment and disaster recovery using the mechanisms that exist. As we’ve seen over the last two days, we learn, recover and move forward most effectively when we collaborate and work together.” – Microsoft, 20 July 2024
A big issue also hovers over the landscape, what the Guardian describes as monopolisation in a report yesterday. Does this single centralised point of failure spotlight the huge risk of having all our IT eggs in a single basket?
“It’s not just that so many firms rely on CrowdStrike, but that cloud infrastructure relies on hugely powerful companies such as Microsoft, which then subject firms to exclusionary and anticompetitive practices that concentrate services and offerings into an increasingly narrow range of options.” – Guardian, 20 July 2024
It’s probably fair to say that this IT meltdown will have resulted in billions in losses as businesses worldwide face downtime, lost revenue, and recovery costs. Actual recovery will likely take some time, with consequential effects lingering for days, if not weeks.
Now, let’s consider communication during the initial days of the crisis and what should come next.
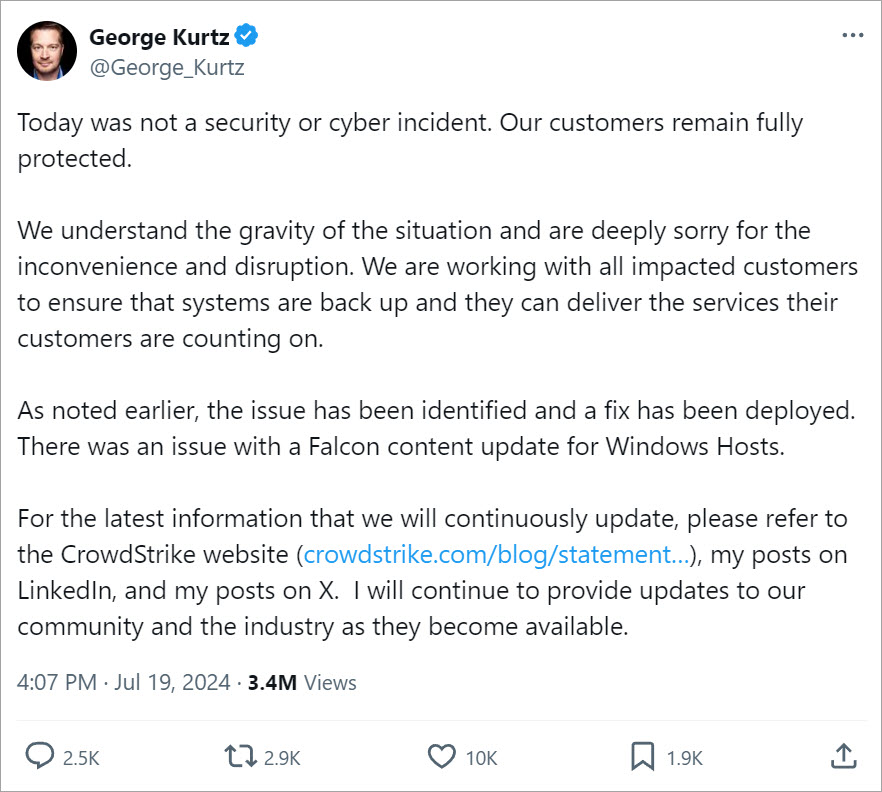
CrowdStrike’s approach from the start of the outage demonstrated several best practices in crisis communication. They were quick to publish a statement from founder and CEO, George Kurtz, with an apology (and thus implicit ownership of fault), establish an update reporting structure via their support website and blog, and make a commitment to resolution and future improvements – an overall approach likely to help maintain trust with customers and stakeholders during this challenging situation.
Kurtz has also been visible and active on social networks, notably X and LinkedIn.
CrowdStrike published detailed information on the technical aspects of the outage, including what happened, the impact, and technical details about the affected systems – a level of detail to help IT professionals understand the issue and its implications.
There’s a live Wikipedia page with updates by many volunteer editors that describes the timeline of events.
A Clear Call To Action
All this is very good. But, at this stage, it’s important to fully understand all the circumstances surrounding this calamitous outcome from a routine update for Windows instead of just priming social media with ongoing explainers that will struggle to maintain focus and momentum on all the key elements of this crisis amidst conflicting and at times confusing reports and opinions on what’s going on.
It’s crucial for CrowdStrike and Microsoft to work hand-in-hand, not just in resolving this immediate crisis, but in rebuilding trust in the technologies that underpin our digital world. We need a comprehensive post-mortem analysis that goes beyond technical fixes to address the systemic vulnerabilities exposed by this incident, and a communication plan that majors on authenticity, facts and trust.
For business leaders, this serves as a wake-up call to reassess their cybersecurity strategies and crisis preparedness. It’s time to have serious conversations about redundancy, disaster recovery, and the risks of over-reliance on single vendors (and the risks of monopolisation).
It’s unquestionably a huge task, but one that is critical and must begin straightaway.




